
개요
흥미를 끌기 위해 안드로이드와 라즈베리파이란 단어를 사용하게 되었다. 우선적으로 모든 하드웨어에 대응하고 구현하는 것은 매우 어렵다. 그렇기에 확장 가능하고 유연한 라이브러리로 구성되어 있다. 따라서 Tensorflow는 기본적으로 X86 CPU나 CUDA와 같은 중요하고 기본적인 기능만 구현한 뒤, 나머지 기능은 모두 써드파티 라이브러리에게 위임하고 있다.
Tensorflow에서 X86이나 CUDA와 같은 장비(명령어)외에 딥 러닝 연산을 수행하는 경우를 볼 수 있다. 대표적인 사례가 Google TPU가 있을것이고, Android 계열의 NPU, 또는 Arm CPU가 있다. 그렇다면 이런, 장비들은 어떻게 Tensorflow에서 연산이 가능한지 의문이 생길것이다.
구현 방식은 크게 2가지 방법이 있다. 첫번째는 Tensorflow에서 딥 러닝 학습 과정을 마무리하고 나온 결과물 pb와 tflite를 파싱하여 구현하는 방식이 있다. 두번째는 Tensorflow의 Delegate(위임자)를 통해 Tensorflow의 기능 확장하는 방식이 있다. 물론, 두개 모두 구현되어 있는 사례도 존재한다.
안드로이드에서 Tensorflow 라이브러리 호출 과정
필자는 Arm에서 딥러닝 연산 최적화를 수행하기 위해 1년 정도 공부를 하였다. 현재는 ArmCL, ArmNN에 대한 모든 코드를 읽고 숙지하였고, 원하는대로 수정까지 가능한 수준이다. 그리고 ArmCL에 성능적인 이슈가 있어, 관련 문제를 해결하고 논문 투고까지 한 상태이다.
이해하기 앞서, 안드로이드와 라즈베리파이이나 애플의 M 계열의 맥북는 Arm CPU로 구현 되어 있다. 그리고, 딥 러닝은 고도로 최적화가 필요하므로 여러 단계와 라이브러리로 구현되어 있다.
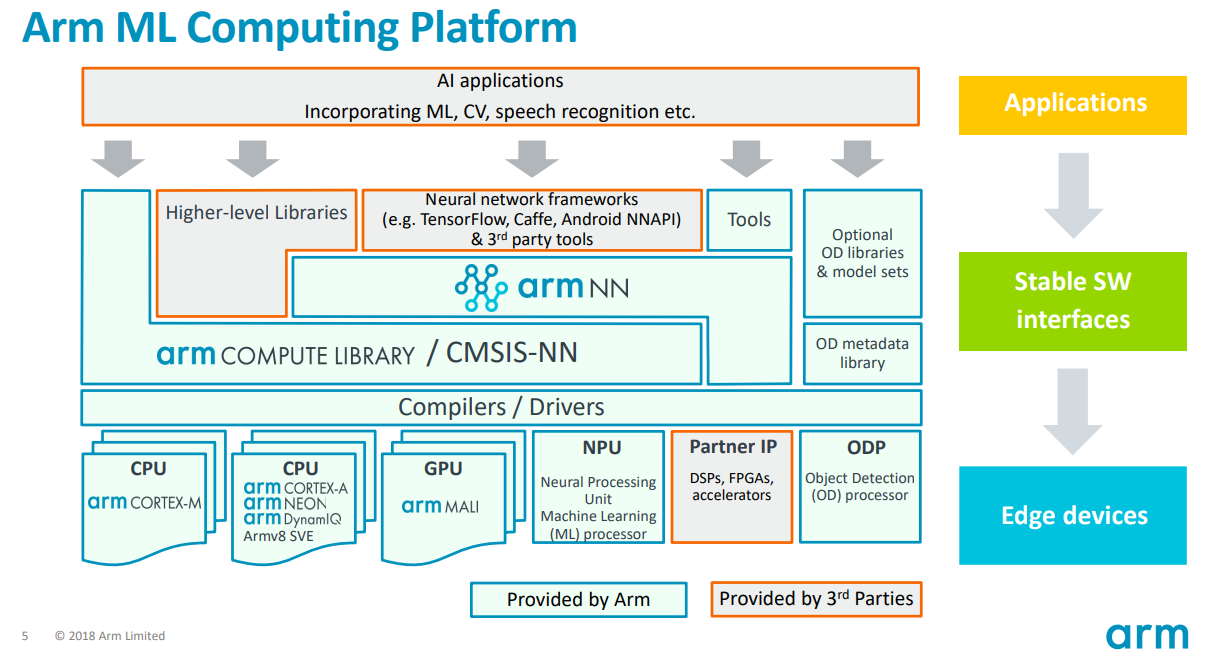
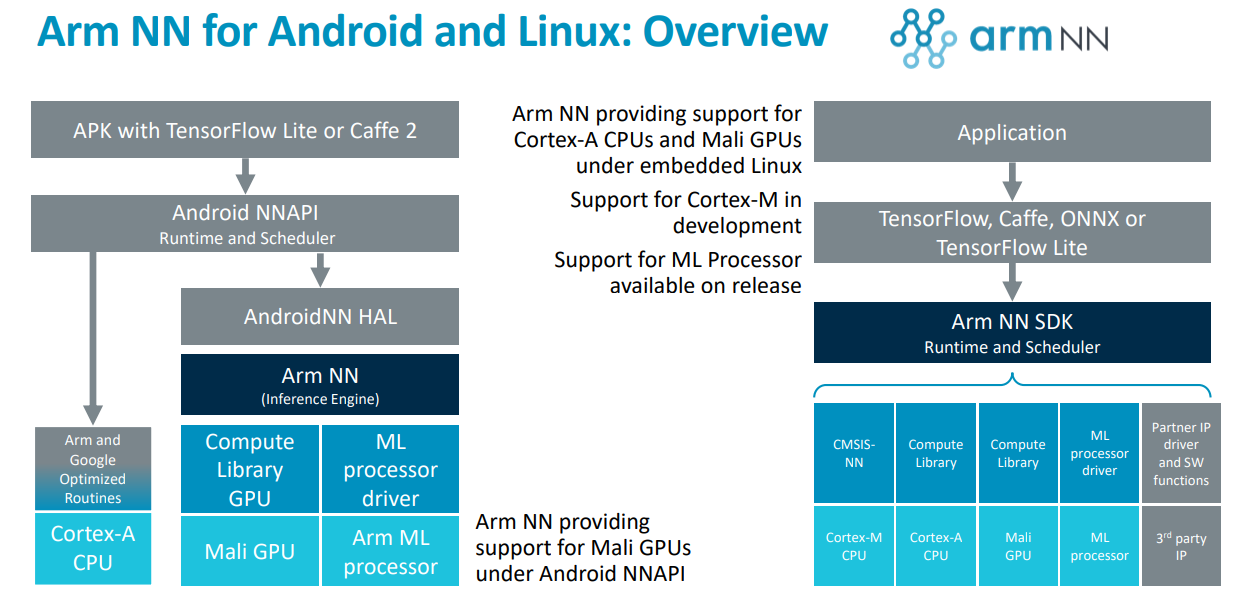
아래의 그림을 본다면 단순하게 Tensorflow에서 딥러닝 연산을 요청하면 ArmNN(Arm Neural Network) 라이브러리를 호출하게 되고, ArmNN에서 ArmCL(Arm Compute Library)를 통해 CPU 와 GPU를 호출하여 연산을 수행하게 된다.
각 단계로 차례로 나열하자면 아래와 같다.
- Application : 안드로이드의 어플, Python으로 구현된 응용 프로그램
- Tensorflow : 접근성이 높은 라이브러리(최종 사용자가 사용하기 쉬움)
- ArmNN : Tensorflow와 ArmCL간의 연결 고리(단독으로 사용시 TFLite와 ONNX 파일 포맷을 지원함)
- ArmCL : Arm CPU 와 GPU를 어셈블리 단위로 최적화된 라이브러리

더 심연으로
ArmNN과 ArmCL의 관계
ArmCL은 Arm CPU와 GPU를 어셈블리 단위로 최적화된 라이브러리라 기술하였고, ArmNN은 TFLite와 ONNX를 파싱한 결과를 ArmCL에서 연산이 가능하도록 변환하는 라이브러리라 보면 된다.
ArmCL에 구현된 방식
우선 ArmCL에 대해서 알아보자면, ArmCL은 Mali GPU와 Arm CPU를 지원하고 있다. Mali GPU는 OpenCL 언어로 구현이 되어 있으며, Arm CPU는 Arm NEON(SIMD, Single Instruction Multi Data, 1개의 명령어 싸이클로 N개의 데이터를 병렬 처리하는 기법)을 활용하여 구현되어 있다.
ArmNN에서 ArmCL의 예외처리
ArmNN에서는 ArmCL에서 Arm NEON으로 구현한 것을 CpuAcc라 부르고 OpenCL로 구현한 것을 GpuAcc라 설명하고 있다.
대부분의 경우 GPU가 딥 러닝 추론하는것이 더 높은 성능을 가지겠지만, 간헐적으로 GPU에서 연산이 불가능한 사례도 있다(Concatenate 연산자(2개 이상의 텐서를 합치는 연산자)). 이런 에외 상황은 ArmCL에서는 대응이 되어 있지 않지만, ArmNN에서 예외처리가 되어 있다.
그래서 Gpu에서 우선적으로 연산을 수행하고, 만약 없는 연산자라면 Cpu에서 연산을 수행하도록 우선순위이란 개념을 통해 해결이 되어 있다. 만약 CpuAcc와 GpuAcc를 통해서 딥 러닝 추론이 불가능한 경우(구현된 Ops가 없다면?) 어떻게 추론을 할 것인가?
그런 경우 Arm NEON이나 OpenCL을 통해 연산 가속하는 것이 아닌, 단순 반복문인 C++14의 표준 프레임워크를 이용하여 구현되어 있다.
요약
- ArmCL : Arm NEON과 OpenCL을 통해 Arm에서 딥 러닝 가속 라이브러리
- ArmNN :
- TFLite와 ONNX 파일을 읽고 ArmCL에 적합한 형태로 변환함.
- Tensorflow Delegate에 맞춰 명령어를 ArmNN 모델로 변환함.
- Tensorflow :
- Delegate를 제공함.
- 최종 사용자에게 최대한 친숙하도록 구현이 되어있음.
요약
최종 사용자에게는 엄청 간단하고 명료하게 사용이 가능하지만 실질적으로 내부적의 구현은 매우 복잡하고, 때론 아름답게 구현이 되기도 합니다.
아래의 코드는 Tensorflow의 MNIST의 예제 코드 중 하나입니다. 아래의 코드는 model을 생성하고 컴파일, 그 이후에 fit을 하는 과정입니다.
이때 Compile이란 함수는 진정한 의미로 컴파일러를 통해 컴파일을 수행하기도 하며, 모델의 내부 구조를 확정 짓는 과정을 나타냅니다.
필자는 compile 함수와 evaluate 함수에서 명령어를 생성하고 안드로이드에서 연산하는 과정을 나타냈습니다.
3줄 요약 :
- 라즈베리파이나 안드로이드에서 딥 러닝 연산을 수행한다면, ONNX Runtime을 사용해서 하시는게 젤 맘편하십니다.
- 느리다면 NCNN을 이용하시는것도 좋습니다.
- 솔직히 ArmCL과 ArmNN에 대해서 몰라도 전혀 문제가 되지 않습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()],
)
model.fit(
ds_train,
epochs=6,
validation_data=ds_test,
)