
개요
코딩은 언제나 즐겁고 나를 재밌게 만들어준다. 필자가 학부생일 때, 만들고 운영했던 저지 사이트는 현재 하나의 학과 중간/기말고사에 쓰여지고 있다. 또한, 학과에서 학생이 직접 문제를 만들어서 사이트에 올릴 수 있고, 필자는 졸업했음에도 불구하고 아직까지 문제 생성 권한이 남아있다. [학괴 저지 사이트] 그래서, 단순히 백준이나 프로그래머스에서 쉽게 볼 수 있는 알고리즘 문제가 아닌 뭔가 다이나믹하고 머리에 짜릿한 문제를 만들기 위해서 고심하던 중 MNIST를 이미지 데이터셋이 주어지고, 어떠한 숫자인지 판별하는 코드를 작성하도록 하면 정말 재미있을 것이라 생각하게 되었다.
현재 MNIST는 NLP에 비해 인기가 많이 식었지만, 아직까지도 인공지능 공부한다면 거의 반드시 접하게 되는 데이터 셋 중 하나이다. 그렇기 때문에 딥 러닝뿐만 아니라 SVM, Bayesian, 기타 등등을 직접 구현하여 이미지가 입력이 되었을 때, 숫자를 판별하는건 쉬울 것이라 생각하였다. 다만, 학과 저지 사이트의 경우에는 한계점이 존재했는데, 네트워크 통신 금지, 어셈블리 금지, 시스템 커널 직접 접근 금지, 외부 라이브러리 금지, 쓰레드 활용 금지 와 같이 제약사항이 많다. 여기에서 그쳤다면 정말 좋았겠지만, 안타깝게도 소스코드의 용량 제한이 있다. 무려 약 30kb이상 넘는 코드를 제출 할 경우 저지 시스템 레벨에서 제출을 금하는 것이다.
그렇기 때문에 직접 코드를 구현하여야하며, 30kb가 넘지 않는 코드를 작성해야한다는 것이다.
시스템 구조 설계
필자의 경우에는 MNIST의 이미지가 입력이 되었을 때, 숫자 정보를 추출하기 위해서 딥 러닝 모델을 활용하였다. 따라서 전체적인 시스템은 크게 3가지의 파트로 나눠진다.
- 인공지능 모델 : 파이썬과 텐서플로우를 통해
MNIST의 이미지가 어떠한 숫자인지 판별하는 인공지능 모델을 생성 - 모델의 가중치를 C++ 코드로 변환 : 텐서플로우를 통해 가중치 정보를
JinJa2템플릿 엔진을 통해 C++ 코드 생성 - 저지 사이트에 제출 가능한 C++ 단일 파일 생성 : CMakeLists를 통해
MNIST Inference Engine바이너리 생성
인공지능 모델 생성
인공지능 모델을 학습 하는 것은 정말 쉽고 간단하다. 이를 증명하듯이, 텐서플로우나 파이토치 사이트에서 기본적인 학습용 코드를 제공하고 있다. [학습용 코드]. 하이퍼 링크로 건 곳은 Tensorflow에서 MNIST를 학습용으로 만든 것이며, 필자가 사용한 인공지능 모델을 기반으로 만든 것이다.
저지 사이트의 한계점으로 인하여, (1x28x28) 이미지를 그대로 Dense나 Convolution 으로 만들게 될 경우 생성되는 weight의 양으로 인하여 30kb가 초과하였기 때문에, 어쩔 수 없이 이미지를 Downscaling 한 뒤 Dense로 연산을 수행하도록 하였다. 이때, Downscaling을 조금 더 직관적이고 신경망 모델에서 동작한다는 느낌을 주기 위해 Average Pooling로 표현하였다. 그 이후에는 이 글을 읽는 모두가 다 알 것이라 예상하듯이, 평탄화하고, Dense와 Activate 함수로 대충 연결해 주었다.
자세한 코드는 [Train model and Save H5] 에 기술 되어져 있다.
1
2
3
4
5
6
7
Input (1 x 28 x 28) ->
Average Pooling (1 x 7 x 7) ->
Flatten (1 x 49) ->
Dense (1 x 49 x 30) ->
ReLu (Activate) ->
Dense (1 x 30 x 10) ->
Output (1 x 10)
모델 가중치를 C++ 코드로 변환
H5 모델과 신경망 모델 구조에 대한 정보를 가지고 있으므로, 이를 numpy나 출력 가능한 형태로만 만들 수 있다면 무엇이든지 만사 OK이다. 그 이유로는 아래와 같이 미리 만들어놓은 template.hpp 코드가 있고, 이를 JinJa2 Template Engine이 ``에 값을 채워넣어 줄 것이기 때문이다.
1
2
3
4
constexpr std::array<std::array<float, 49>, 30> dense1_weight { };
constexpr std::array<float, 30> dense1_bias { };
constexpr std::array<std::array<float, 30>, 10> dense2_weight { };
constexpr std::array<float, 10> dense2_bias { };
먼저 JinJa2 를 모르는 사람이 있을지도 몰라, 간단하게 설명하자면, 반복문, 조건문, 값 치환 등이 가능한 Template 엔진 중 하나이다. 필자는 잘 모르겠지만, 백엔드 개발에서 NodeJS나 DJango에서 HTML 파일 Serving할 때 많이 쓰인다고 본적이 있다.
무튼, 바로 본론으로 들어가자면 [Convert H5 to CPP] 코드에서 JinJa2 템플릿을 렌더링을 하면서 C++ 코드를 생성하는 것을 볼 수 있다.
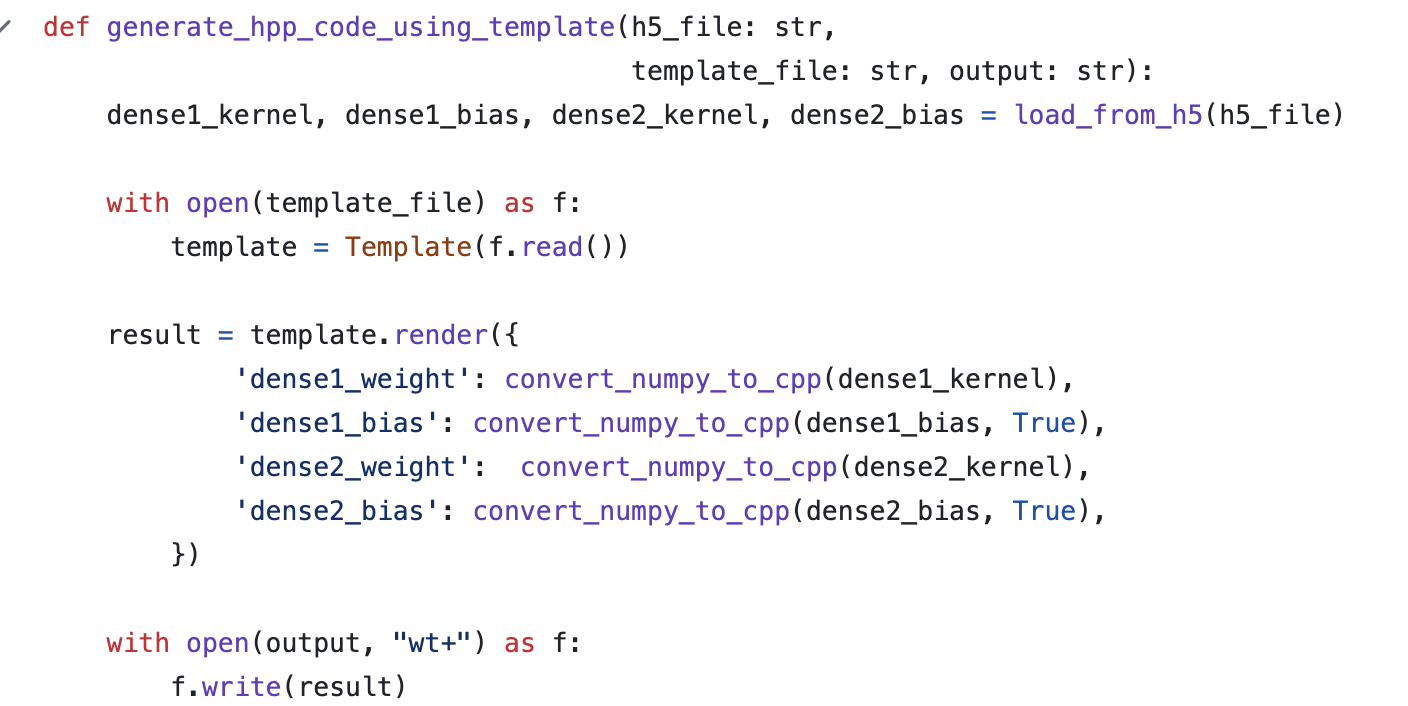
그러면 아래와 같은 C++ 코드를 결과물로써 얻어 볼 수가 있다.

저지 사이트에 제출 가능한 C++ 단일 파일 생성
이제 Keras의 H5 파일의 가중치 데이터를 모두 C++ 코드 영역으로 가지고 왔다면 더 이상 tensorflow나 keras, h5와 같은 종속성은 모두 필요 없으며 이제 순수 C++ 형태로 구성이 된다.
C++ 의 특성을 활용해서 #include "weights.txt" 하도록 하여 원하는 지점에 가중치 파일을 삽입하도록 하였다. 필자의 경우, 가중치 데이터를 프로그램이 메모리에 적재될 때 함께 메모리에 적재되도록 하기 위해서 전역 변수로, constexpr static std::array<>로 정의하였다.
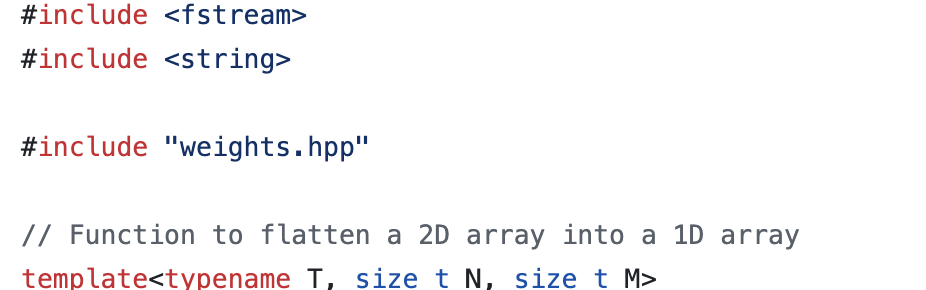
이후로는 모두가 다 알다 싶이 g++이나 msvc, mingw, clang++으로 빌드를 수행하면 되며, 저지 사이트에 제출하고 싶다면 메뉴얼하게 직접 코드를 Copy&Paste 하면 된다. 그러면 MNIST 추론이 가능한 실행 가능한 바이너리가 쨔쟌 하고 생성이 된다.
재현성 (필요하다면)
딥 러닝의 대부분은 랜덤성으로 다뤄지므로 재현성이 매우 중요하다고 필자는 생각한다. 또한, 필자는 글 보다는 코드를 보면서 코드에 대한 근거나 이유에 생각하는 것이 편하기 때문에 코드를 쉽게 따라 할 수 있도록 만들었다.
레포지토리와 빌드 과정에 대해서 간략하게나마 기술한다.
1
2
3
4
$ git clone https://github.com/Piorosen/implement-mnist.git
$ cd implement-mnist
$ chmod +x ./scripts/run.sh # setting and build by docker
$ ./scripts/run.sh --all # the number of MNIST dataset from train dataset in tensorflow dataset, nearly 100.