개요
추신. 누구나 읽고 이해하기 편하게 하기 위해 작성한 내용입니다. 논문의 내용의 핵심을 전달하고자 일부 내용이 누락 생략을 할 수 있습니다.
ARM 회사에서 만든 딥러닝 추론 프레임워크인 ACL(Arm Compute Library)에서 코드 분석하던 중, GEMM Direct, GEMM General, Winograd Convolution를 활용하는 것을 알 수 있습니다. [필자가 쓴 논문]에서 크게 3 종류가 있으며, 추가적으로 Naive, FFT(고속 푸리에 연산)을 통해 수행이 되기도 합니다.
GEMM Direct, GEMM General, Winograd, Naive, FFT는 본 문 내용을 설명하기 위해 필요한 내용이 아니므로 따로 설명은 하지 않습니다. 하지만 Indirect Convolution은 GEMM 기반의 컨볼루션 연산을 수행하므로 간단하게 설명으로 진행합니다.
컨볼루션 연산 수행 과정
컨볼루션 연산은 입력 x 필터 커널 = 출력 결과를 수행하는 과정에서 입력 공간과 커널간 곱셈을 수행 한 결과를 모두 더하는 구조로 동작합니다. 예시로 아래의 이미지와 같이 동작을 수행합니다.
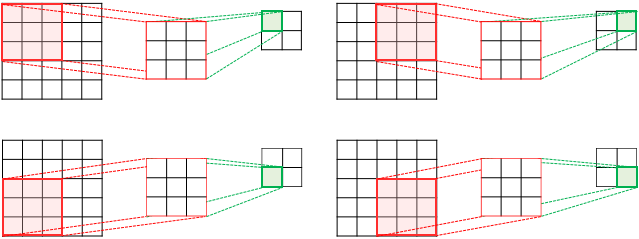
이러한 과정은 컨볼루션 연산 수행하는 과정은 복잡하고 많은 연산시간, 그리고 범용 연산이 아니므로 APU나 하드웨어에 특화되어 있지 않습니다.
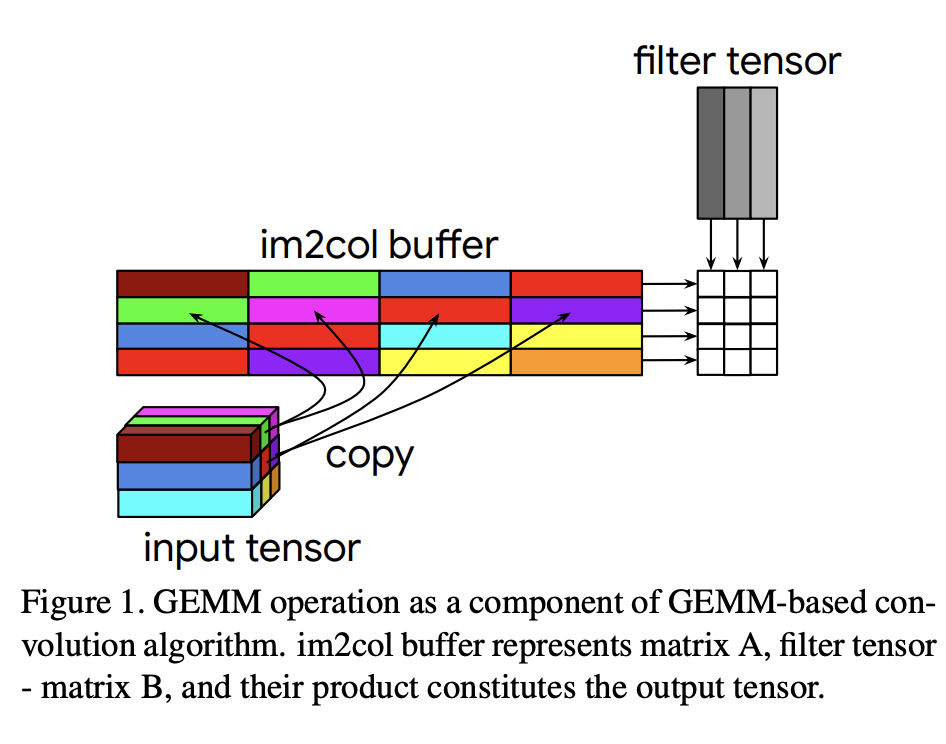
따라서, 이를 조금 더 빠르게 연산을 수행하기 위해 행렬로 변환하여 연산하는 기법이 발전하게 되었습니다. 행렬 연산으로 변환하는 과정을 Im2Col 이라 명하고, 변환 된 행렬 구조를 연산 하는 것을 GEMM(GEneral Matrix-Matrix)라고 말합니다. 마지막으로 행렬을 다시 컨볼루션 구조로 변환하는 것이 Col2Im이라 합니다.
이를 통해 컨볼루션 연산이 행렬 연산으로 변환됨으로 써 GPU나 CPU의 SIMD(Single instruction, multiple data)로 연산 가속화가 가능하게 되어졌습니다. 물론, Im2Col, Col2Im은 메모리의 Arrange 재 구조화하여야 하므로 여전히 병목현상으로 나타납니다.
논문의 핵심 요지
컨볼루션 연산을 수행하는 과정에서 Im2Col과 Col2Im은 여전히 병목 현상이고, 이를 없애는 것이 가능하다면 없애서 병목 문제를 최소화 할 수 있습니다. 따라서 본 논문에서는 메모리를 직접 접근하여 데이터를 읽어가는 구조가 아닌, 포인터 배열로 데이터를 간접적으로 접근한다면 Im2Col을 생략할 수 있다는 내용 입니다.
그리고 딥 러닝 모델의 가중치 값이 NHWC 구조인 경우 Col2Im을 생략할 수 있다는 부분을 착안하여 GEMM 연산만 수행하여 컨볼루션을 수행할수 있음을 제안하였습니다.
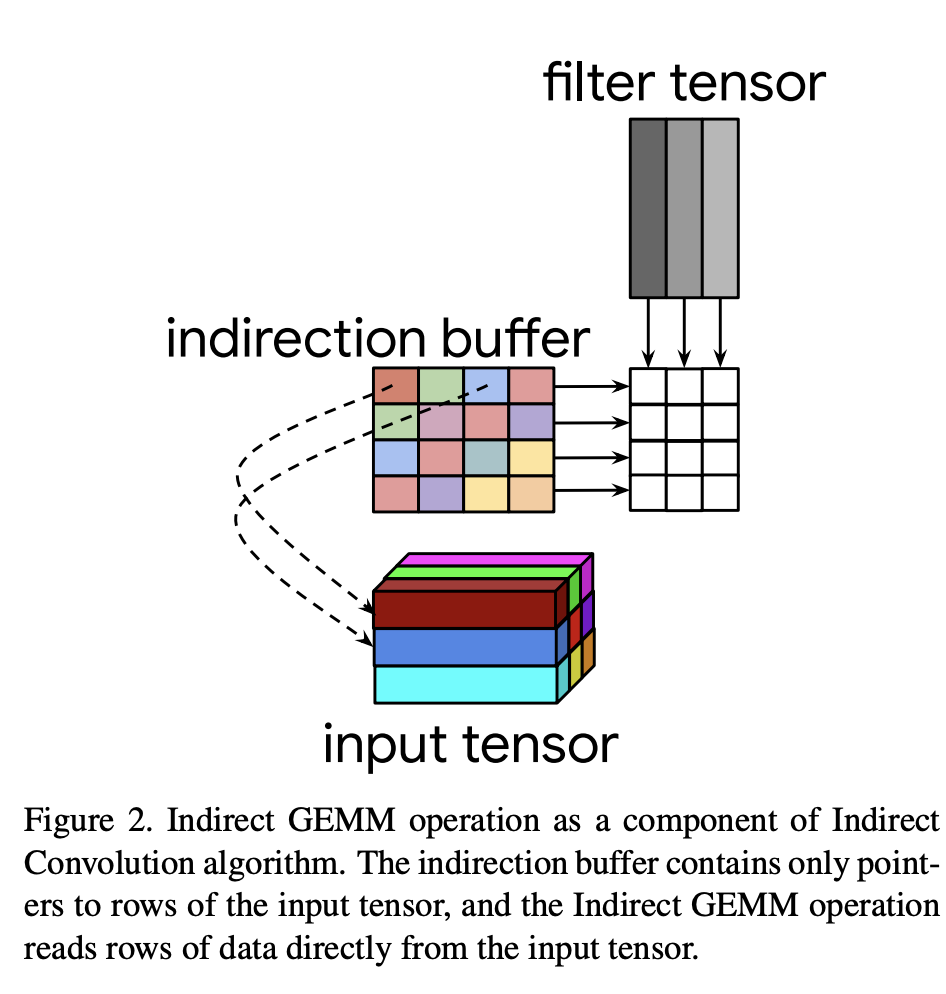
이때, 간접 컨볼루션은 Im2Col을 수행하지 않고, 연산하기 위해 사전에 1회 연산하여 Im2Col 와 동일한 버퍼를 생성합니다.
그 이후에, Im2Col 버퍼에 Input Tensor의 값을 복사하는 것이 아닌, Inpu Tensor의 값이 있는 주소값을 가르키도록 변경합니다. 해당 결과물은 아래의 이미지와 같이 간접 버퍼를 생성합니다.
즉,간접 버퍼를 생성하는 과정에서 “주소값을” 가르키는 것이므로, 원본 값이 변경이 되더라도 간접 버퍼는 주소값이 변경이 되지 않으므로 더 이상 데이터를 복사할 이유가 없어지게 됩니다.
따라서, 최초 1회의 Im2Col을 수행하고 나면 Im2Col이 생략이 되고, Col2Im은 NHWC 구조에서 생략이 되므로 GEMM 연산 만으로 컨볼루션 연산이 가능하게 됩니다.
장/단점
장점
본 논문에서 얻게 되는 장 단점으로는 메모리 재구조화하는 과정이 없어지므로, 이에 대한 비용은 없어지게 됩니다. 그 외에 Stride나 Padding연산에서 쓸모 없는 데이터를 삭제하여 캐시 메모리에 적합한 구조로 변경이 가능합니다.
예시로, Stride의 값이 2인 경우에 Im2Col을 수행하더라도 캐시 메모리 구조에 적합한 형태가 아니므로 잦은 캐시 미스가 발생하지만, 간접 버퍼를 이용한다면 버퍼가 가르키는 주소 값을 캐시 Aware한 구조로 생성할 수 있습니다.
이를 통해 Stride, Padding 특정 크기 이상의 필터 커널을 가진 경우에 성능 향상을 꾀 할수 있습니다.
단점
- 1x1 사이즈의 필터 커널는 특수한 형태이므로,
Im2Col없이 바로GEMM연산이 가능합니다. (이는Im2Col의 특성으로 인해 가능합니다.) 이는 간접 컨볼루션이 없는 것이 오히려 이득이 되는 사례 입니다. NCHW가 아닌NHWC의 구조에 특화가 되어 있습니다.
실험 결과
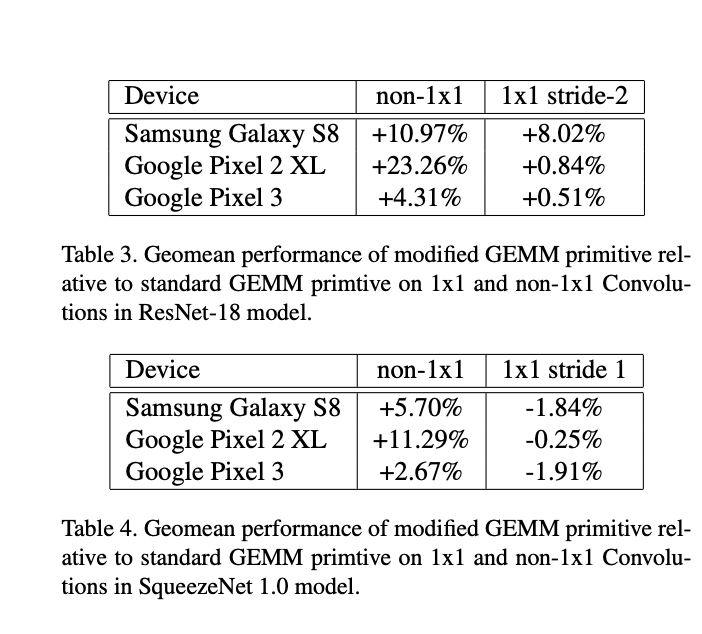
본 논문에서는 삼설 갤럭시 S8, 픽셀 2 XL, 픽셀 3 에서 실험을 하였고, 1x1 + stride-2 에서는 일부 성능 향상이 있었지만, stride-1인 경우엔, 예상 결과대로 성능 저하가 발생하였음을 알 수 있습니다.
그리고 1x1 필터 사이즈가 아닌 경우에는 대부분 효과적으로 성능 향상이 되었음을 알 수 있습니다.